

The AI Vulnerability Surge: Transforming Vulnerability Management

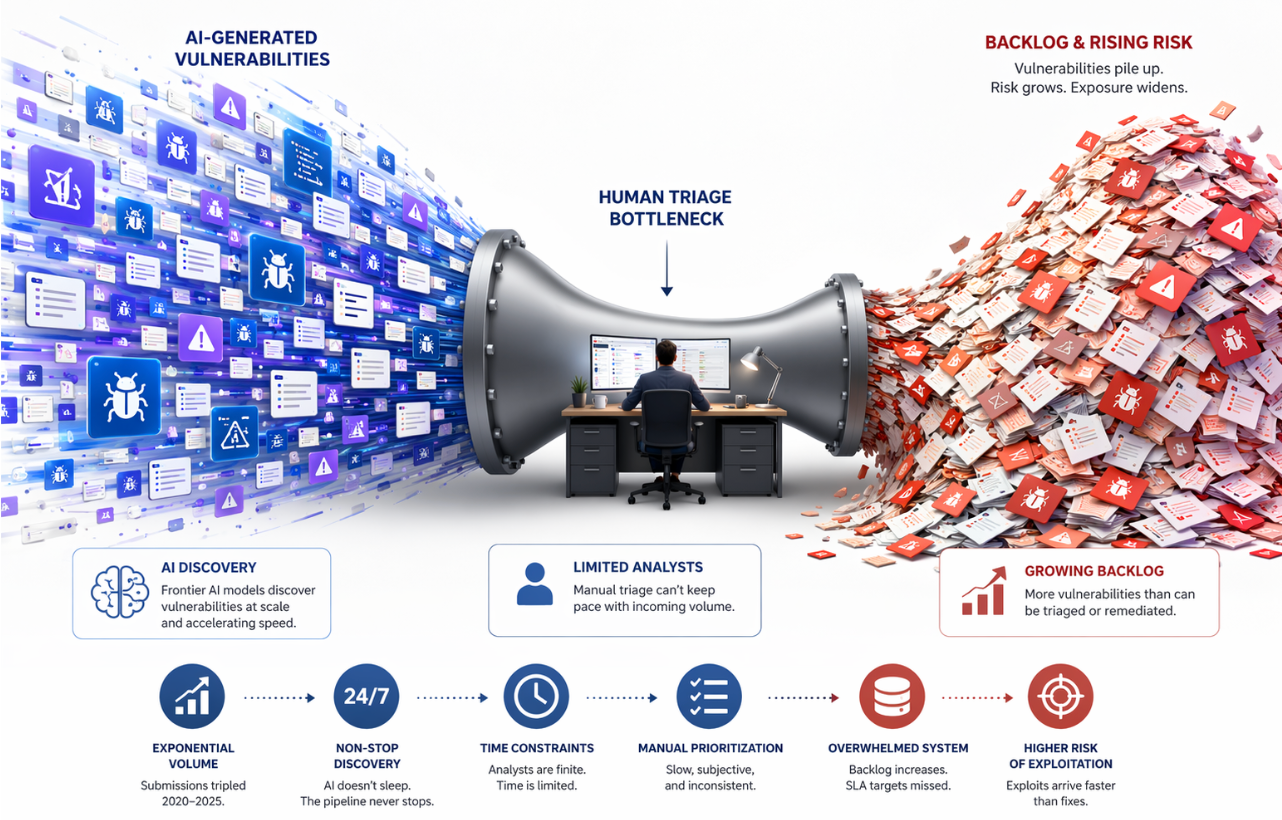
For nearly two decades, the vulnerability management pipeline remained effective because it was inherently balanced around human effort. Vulnerabilities were discovered, enriched, triaged, and remediated by people, and each stage of the process operated at roughly the same pace. This equilibrium has now been disrupted. Detection has evolved from human-driven discovery to exponentially faster, AI-assisted identification, powered by frontier models such as Mythos and DayBreak. As a result, the volume and velocity of newly identified vulnerabilities have outpaced the capacity of traditional enrichment and triage processes.
In response to this structural imbalance, NIST transitioned the National Vulnerability Database (NVD) to a risk-based prioritization model in April 2026, focusing enrichment efforts only on a subset of high-priority vulnerabilities. The system is no longer designed for comprehensive coverage; it is adapting to survive at current scale. And the challenge extends beyond known CVEs. AI-driven discovery is increasingly surfacing exploitable issues that never enter the CVE pipeline at all, creating a category of risk that traditional triage workflows were never built to handle.
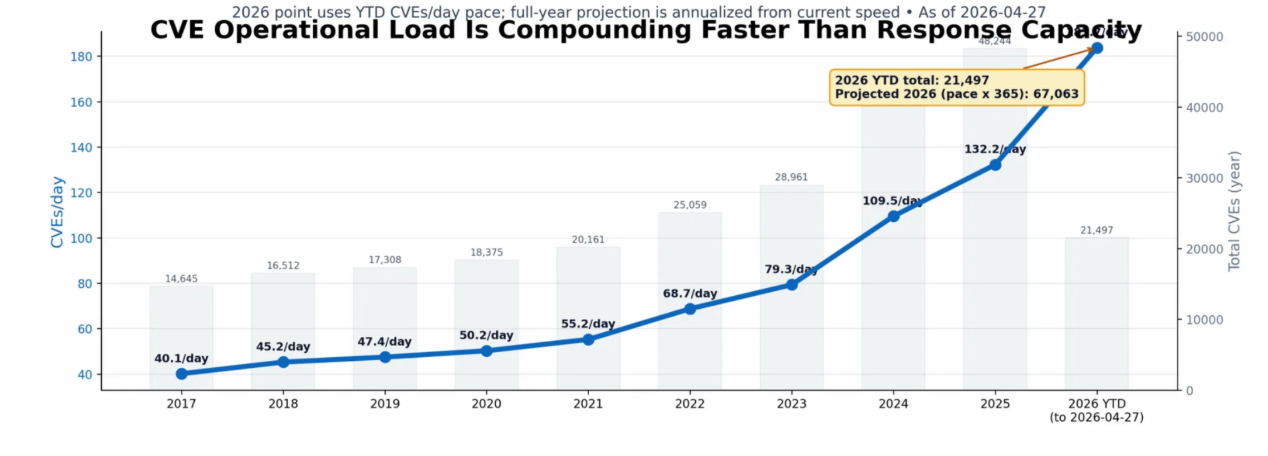
Discovery got faster, exploitability got cheaper
The bottleneck has shifted decisively to triage and remediation. Organizations today detect approximately 500 vulnerabilities per day but can manually remediate only around 20-creating a growing backlog and an average remediation lag of nearly 49 days. At the same time, the threat window is compressing: nearly 28.96% of Known Exploited Vulnerabilities are exploited on or before their CVE publication date, rendering traditional 30 to 90 day patch SLAs increasingly ineffective.
The implication is clear: security programs are no longer constrained by their ability to detect vulnerabilities, but by their capacity to process, prioritize, and remediate them effectively. The core challenge has shifted from incremental optimization to fundamentally rethinking operating models to function at AI-scale velocity. The gap is not due to a lack of scanning capabilities; rather, it reflects the absence of robust prioritization frameworks and validated automation needed to support triage and remediation at the volume and speed demanded by the current threat landscape.
Beyond NVD: building resilient enrichment and context pipelines
The infrastructure challenge further amplifies the prioritization problem, particularly as NVD enrichment can no longer be assumed to provide complete coverage at scale. Under NIST’s updated model, severity scores, product mappings, and structured metadata are increasingly incomplete, with some CVEs explicitly deprioritized and not immediately enriched. These gaps are not merely cosmetic-the resulting failure mode is often silent, with pipeline limitations only becoming visible during incident reviews.
In this context, many organizations are beginning to broaden their enrichment strategies beyond sole reliance on NVD. Incorporating complementary sources such as CISA’s KEV catalogue, EPSS scores from FIRST, vendor-specific CNA feeds, and commercial threat intelligence helps provide more comprehensive and timely context. It is also useful to periodically review existing pipelines to understand which downstream processes depend on full NVD enrichment and how they behave when that coverage is partial or unavailable.
Two capabilities help reduce this noise before triage begins. SBOM and VEX coverage allows teams to programmatically determine whether a vulnerability actually applies to a specific deployment, filtering non-applicable findings with supporting evidence. Deduplication is equally important: most organizations run 8 to 12 security tools, and the same vulnerability commonly surfaces as separate findings across SAST, SCA, container scanning, and DAST. A significant portion of the "500 findings per day" figure is duplicated. Without normalization across tool outputs, triage operates on noise alongside signal, and teams end up prioritizing the same issue multiple times through different lenses.
From severity to exploitability: rethinking vulnerability prioritization
Traditional prioritization approaches relying on CVSS worked reasonably well when vulnerability volume was low and enrichment data was consistently available. However, CVSS was never designed to function as a prioritization system. At current scale, treating it as one creates a systemic failure mode: large backlogs where everything appears equally urgent, yet little meaningful remediation occurs.
Effective prioritization now requires a layered, multi-signal approach. The most practical model treats CVSS as a baseline input, not the decision point. From there, additional signals must be applied to progressively refine risk and focus efforts on what is truly exploitable. A robust prioritization stack incorporates Known Exploited Vulnerability (KEV) status, Exploit Prediction Scoring System (EPSS) probabilities, threat intelligence context, static reachability analysis, and environmental exploitability. Each layer helps narrow findings from “theoretically vulnerable” to “actually risky in this environment right now.” The layered model above is entirely technical. The final filter that actually drives remediation resources is whether a finding touches a revenue-generating system, a customer data store, or a compliance-scoped environment. That asset-to-business-criticality mapping belongs in the enrichment stack, not only in boardroom conversations.
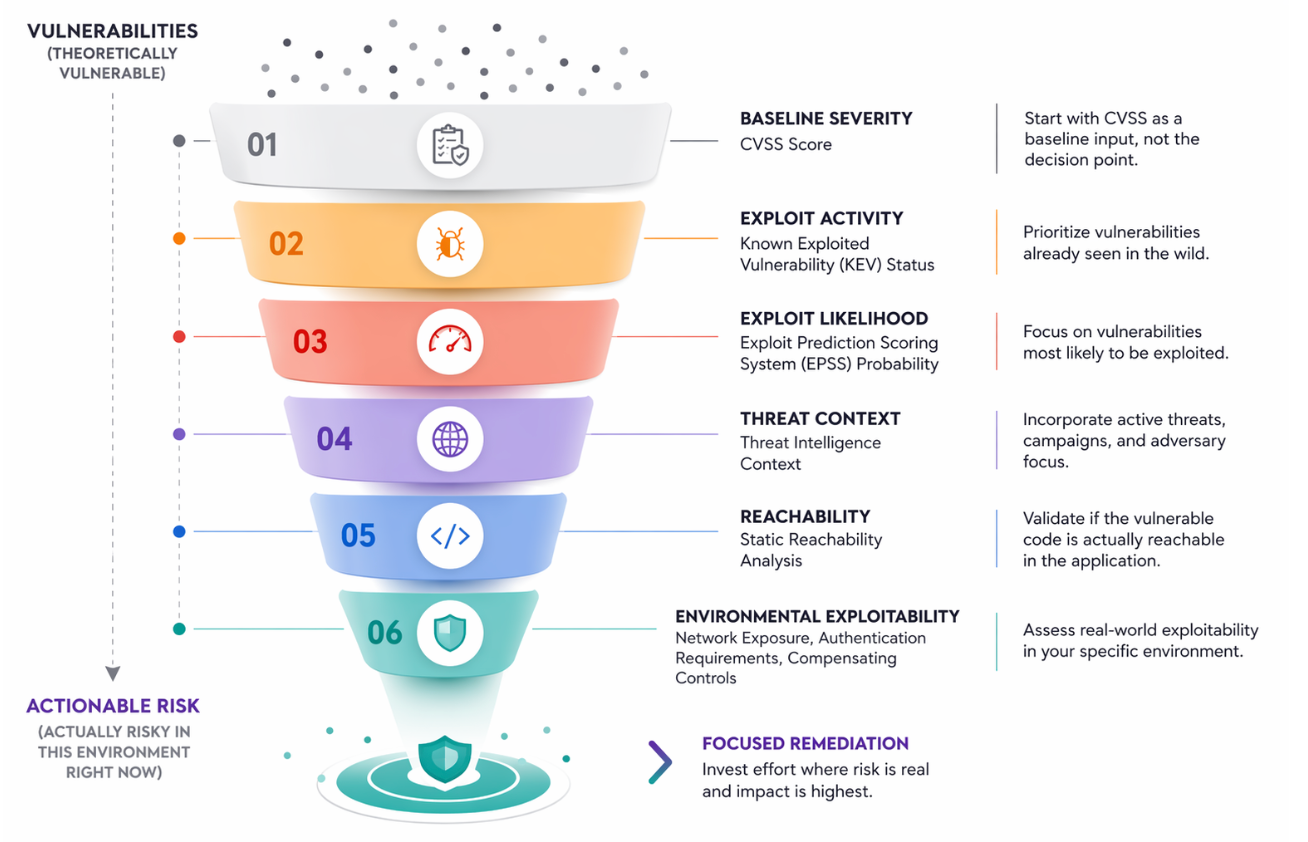
The most common breakdown in prioritization occurs at the reachability stage. Dependency scanners can confirm whether a vulnerable library exists in the build, but they do not answer the critical questions: can the application actually reach the vulnerable function, and is there a realistic attack path in the deployed environment? This gap results in long, noisy vulnerability lists that have a weak correlation with real risk.
In practice, a finding that passes static reachability analysis represents only a possible execution path not proof of exposure. True prioritization requires going further to validate deployment exploitability, accounting for factors such as network exposure, authentication requirements, and compensating controls. These signals distinguish theoretical risk from actionable security exposure. However, most organizations stop at the first question and fail to evaluate the second, leading to misaligned remediation efforts.
The axios CVE-2026-40175 case from April 2026 illustrates this gap clearly. The vulnerability was widely classified as a critical 10/10 issue with potential for cloud compromise. However, deeper technical analysis showed that the exploit chain was not realistically reachable in standard Node.js deployments because runtime header validation prevents the required CRLF injection. While the severity was valid, the actual risk for most environments was limited. Teams that relied solely on CVSS expended engineering effort on low-impact remediation, while those that prioritized based on reachability and exploitability focused on more actionable threats. This is the difference between a 10/10 on paper and a 10/10 in production. And it is exactly the kind of distinction that matters when the pipeline is generating 500 findings per day and analysts have bandwidth to deeply evaluate a fraction of them.
This level of contextual prioritization does not scale through manual analysis alone. It requires enrichment infrastructure capable of continuously applying these signals as part of the triage pipeline, rather than relying on point-in-time assessments when a CVE is published.
A phased approach to auto-remediation
The instinctive response to a 49-day remediation gap is to accelerate patching. However, this approach is ineffective. Vulnerability discovery is scaling faster than remediation capacity can realistically keep pace. Simply increasing effort within the same operating model yields only marginal gains against what is fundamentally a structural problem.
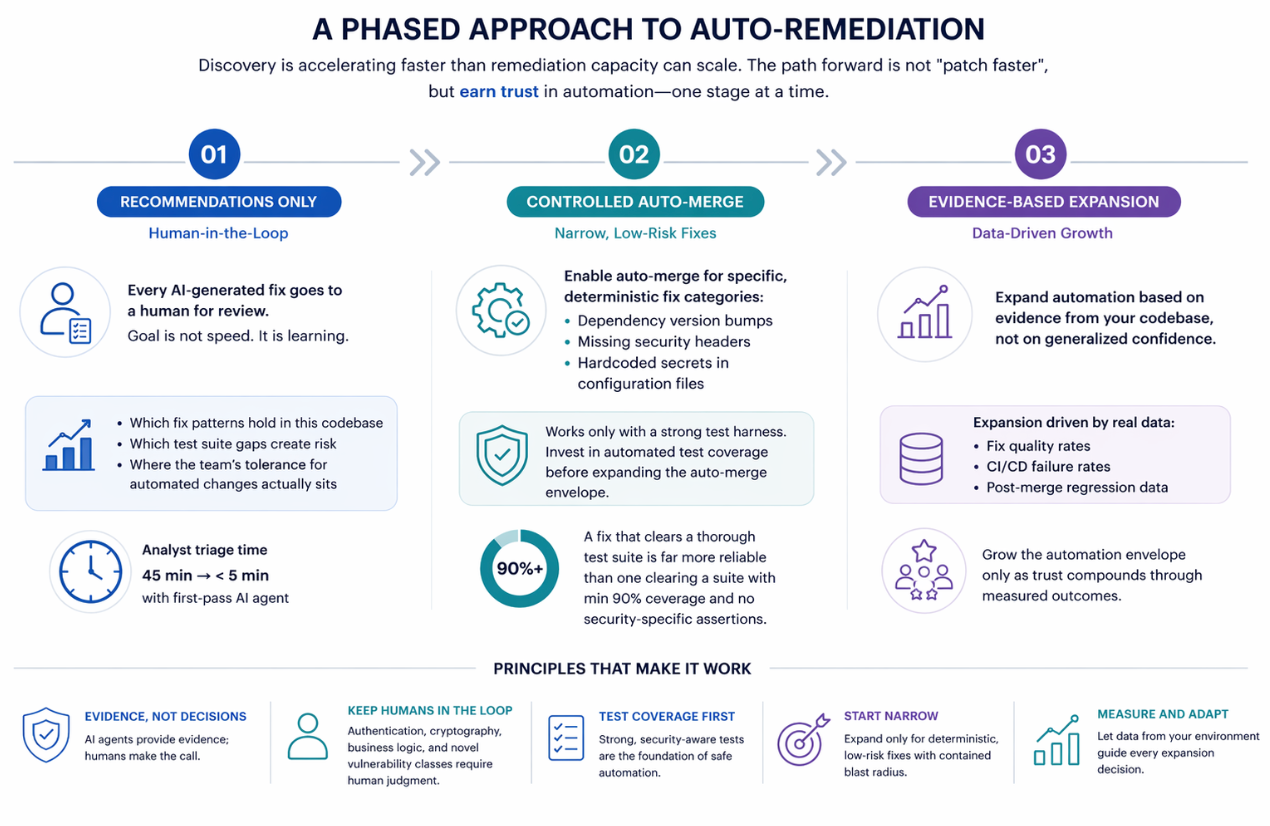
AI agents can meaningfully improve efficiency within this pipeline, particularly at the triage stage. A first-pass agent can enrich findings with reachability context, correlate against KEV and EPSS signals, execute targeted validation scans, and attach supporting evidence to remediation tickets before human review. When implemented effectively, this can reduce analyst triage time from approximately 45 minutes per finding to under 5 minutes. The critical distinction, however, is that agent output must be treated as evidence, not as a decision; the final judgment remains with the analyst.
Certain categories continue to require human expertise, including vulnerabilities involving authentication, cryptography, business logic, and novel exploit patterns. Programs that struggle in this space tend to prematurely expand automated remediation beyond what their validation mechanisms can safely support, often outpacing the maturity of their test coverage.
Organizations making sustained progress approach auto-remediation as a gradual capability, earned through evidence over time rather than enabled as a one-time switch. The most effective model follows a staged progression:
Stage 1: Recommendations Only (Human-in-the-Loop)
All AI-generated fixes are reviewed by humans. The objective is learning, not speed: which patterns hold across the codebase, where test coverage has gaps, and what the organization's tolerance for automated changes actually looks like.
Stage 2: Controlled Auto-Merge for Deterministic Fixes
Automation is introduced for deterministic, low-risk categories such as dependency version upgrades, missing security headers, and hardcoded secrets. This stage depends entirely on test harness strength. There is a material difference between fixes validated by security-aware test suites and those passing superficial coverage thresholds.
Stage 3: Evidence-Based Expansion
The automation envelope expands incrementally based on empirical evidence from the organization’s own environment. Key inputs include fix success rates, CI/CD failure trends, and post-merge regression data. Expansion decisions are driven by real performance metrics, not generalized assumptions about model capabilities.
Key Takeaway
Auto-remediation at scale is not a tooling problem-it is a trust and validation problem. Programs that succeed are those that systematically build confidence in automation through controlled adoption, measurable outcomes, and strong validation pipelines.
Closing the pre-CVE gap with unified asset visibility
The npm supply chain attacks targeting developer endpoints in March 2026 illustrate this gap clearly. In this case, malicious packages distributed through trusted dependency channels deployed a cross-platform remote access trojan and were later attributed by Microsoft to the North Korean state actor Sapphire Sleet. However, the standard vulnerability triage pipeline had no entry point for this incident-there was no CVSS score to reference, no NVD record to enrich, and no KEV status to validate. Instead, detection came through threat intelligence feeds, endpoint detection alerts, or developers observing unexpected behaviour. By that stage, the window for prevention had effectively closed.
A similar dynamic emerged in the Nx Console VS Code extension compromise in May 2026, but from a different perspective. A widely used developer tool was compromised at the extension level, again without a CVE assigned during the critical response window. The relevant question was no longer whether a library was vulnerable, but rather which engineers had the extension installed and whether it had executed. Answering this required endpoint telemetry and device-level visibility-not traditional vulnerability scanning. Teams with strong device inventory and EDR coverage were able to scope exposure within minutes, while others relied on manual outreach, taking hours to reconstruct potential impact.
These incidents highlight a consistent pattern. The teams that responded most effectively did not rely on better tools; they operated with better integration. Specifically, they maintained a unified inventory where software composition analysis, supply chain intelligence, and endpoint telemetry converged into a shared SBOM, CI/CD gating processes, and remediation workflows. When response timelines compressed to minutes, this unified view enabled coordinated action whereas fragmented visibility left teams working with incomplete and inconsistent data.
Building for scale before the incident
The programs navigating this well are not doing anything mysterious. Three patterns show up consistently.
The first is understanding the internals, not just the headlines. Not just knowing that NVD enrichment is changing, but knowing which specific fields are disappearing and what breaks downstream when they do. Not just knowing supply chain attacks happen, but understanding how a CI pipeline can be used against itself. The teams that recovered fastest from the 2026 npm campaigns were the ones that already understood their build trust model before the incident. They also leaned on what was available locally: open source models, internal fine-tuned models, and low-cost inference for initial security validation, rather than waiting for frontier model access to scale their triage.
Second, these programs consistently link vulnerability data to business outcomes. Decisions around remediation are not driven by severity scores alone, but by the impact on critical assets, exposure windows, and potential loss scenarios. The conversations that unlock prioritization and resources are grounded in risk to crown-jewel systems and quantified business impact, rather than counts of high or critical severity findings. As a result, leading teams are building dashboards centred on exposure duration and breach cost, enabling more effective alignment with business priorities.
Third,leading teams are pivoting to proactive defense before incidents necessitate reactive change. By integrating secure coding, threat modeling, and exploitability analysis directly into AI-assisted development lifecycles, they ensure scalability and precision. Ultimately, the most durable strategy shifts from attempting to eliminate all vulnerabilities to minimizing breach impact through architectural controls—such as network segmentation and least-privilege access—with embracing an 'assume breach' mindset.
The overarching takeaway is clear: the constraint is not capability, but execution. Progress comes from systematically strengthening the existing pipeline-introducing missing layers in prioritization, validating resilience under partial enrichment conditions, and operationalizing improvements incrementally. The programs that close this gap will point to the moment when triage, prioritization, and remediation mature into a system that operates at the speed the threat landscape now demands.




.svg)
.svg)

